Dimensionality Reduction
Dimensionality reduction is the process of reducing the number of features (variables) in a dataset while preserving important information. It helps in:
✅ Reducing computational cost (faster processing)
✅ Removing noise from data
✅ Avoiding overfitting
✅ Visualizing high-dimensional data
Types of Dimensionality Reduction
1. Feature Selection (Selecting important features)
- Methods: Correlation analysis, Mutual Information, Recursive Feature Elimination (RFE)
2. Feature Extraction (Creating new compressed features)
- Methods: Principal Component Analysis (PCA), Autoencoders, t-SNE, UMAP
Mathematical Example: PCA (Principal Component Analysis)
PCA is a common method that projects data onto fewer dimensions while maximizing variance.
Example: Reducing 3D data to 2D
Given a dataset:
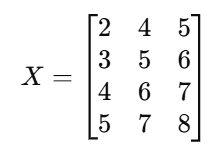
1️⃣ Compute Mean & Center Data
Subtract the mean of each column to center the data.
2️⃣ Compute Covariance Matrix
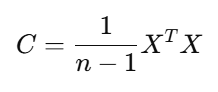
3️⃣ Compute Eigenvalues & Eigenvectors
The top k eigenvectors (principal components) form the new basis.
4️⃣ Transform Data
Multiply the dataset by the top k eigenvectors to get the lower-dimensional representation.